

Since Google’s artificial intelligence (AI) subsidiary DeepMind published a paper a few weeks ago describing a generalist agent they call Gato (which can perform various tasks using the same trained model) and claimed that artificial general intelligence (AGI) can be achieved just via sheer scaling, a heated debate has ensued within the AI community. While it may seem somewhat academic, the reality is that if AGI is just around the corner, our society—including our laws, regulations, and economic models—is not ready for it.
Indeed, thanks to the same trained model, generalist agent Gato is capable of playing Atari, captioning images, chatting, or stacking blocks with a real robot arm. It can also decide, based on its context, whether to output text, join torques, button presses, or other tokens. As such, it does seem a much more versatile AI model than the popular GPT-3, DALL-E 2, PaLM, or Flamingo, which are becoming extremely good at very narrow specific tasks, such as natural language writing, language understanding, or creating images from descriptions.
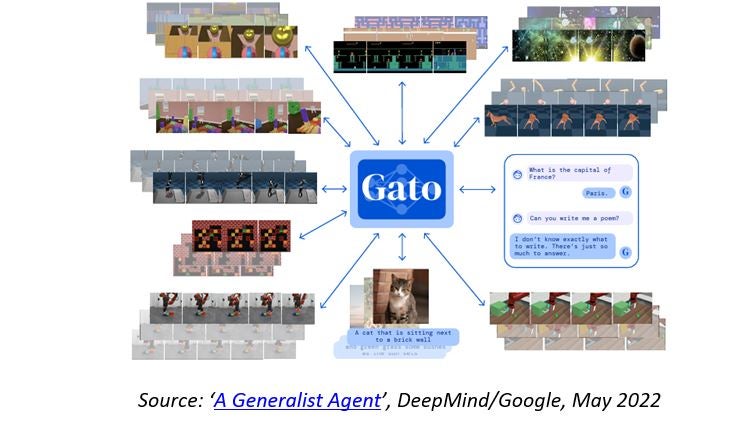
This led DeepMind Scientist and University of Oxford Professor Nando de Freitas to claim that “It’s all about scale now! The Game is Over!” and argue that artificial general intelligence (AGI) can be achieved just via sheer scaling (i.e., larger models, larger training datasets, and more computing power). However, what ‘game’ is Mr. de Freitas talking about? And what is the debate all about?
The AI debate: strong vs weak AI
Before discussing the debate’s specifics and its implications for wider society, it is worth taking a step back to understand the background.
The meaning of the term ‘artificial intelligence’ has changed over the years, but in a high-level and generic way, it can be defined as the field of study of intelligent agents, which refers to any system that perceives its environment and takes actions that maximize its chance of achieving its goals. This definition purposely leaves the matter of whether the agent or machine actually ‘thinks’ out of the picture, as this has been the object of heated debate for a long time. British mathematician Alan Turing advocated back in 1950 in his famous ‘The Imitation Game’ paper that rather than considering if machines can think, we should focus on “whether or not it is possible for machinery to show intelligent behaviour“.
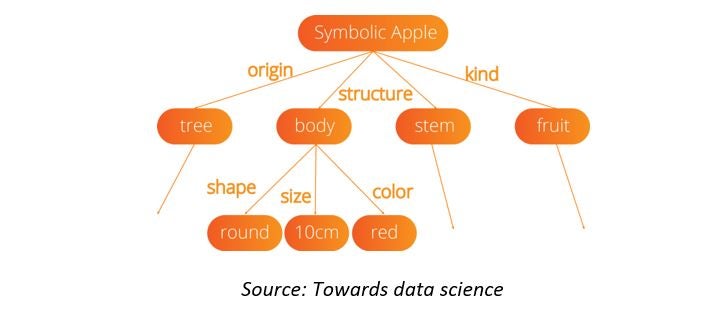
This distinction leads to conceptually two main branches of AI: strong and weak AI. Strong AI, also known as artificial general intelligence (AGI) or general AI, is a theoretical form of AI whereby a machine would require an intelligence equal to humans. As such, it would have a self-aware consciousness that has the ability to solve problems, learn, and plan for the future. This is the most ambitious definition of AI, the ‘holy grail of AI’—but, for now, this remains purely theoretical. The approach to achieving strong AI has typically been around symbolic AI, whereby a machine forms an internal symbolic representation of the ‘world’, both physical and abstract, and therefore can apply rules or reasoning to learn further and take decisions.
While research continues in this field, it has so far had limited success in resolving real-life problems, as the internal or symbolic representations of the world quickly become unmanageable with scale.
Weak AI, also known as ‘narrow AI’, is a less ambitious approach to AI that focuses on performing a specific task, such as answering questions based on user input, recognizing faces, or playing chess, while relying on human interference to define the parameters of its learning algorithms and to provide the relevant training data to ensure accuracy.
However, significantly more progress has been achieved in weak AI, with well-known examples including face recognition algorithms, natural language models like OpenAI’s GPT-n, virtual assistants like Siri or Alexa, Google/DeepMind’s chess-playing program AlphaZero, and, to a certain extent, driverless cars.
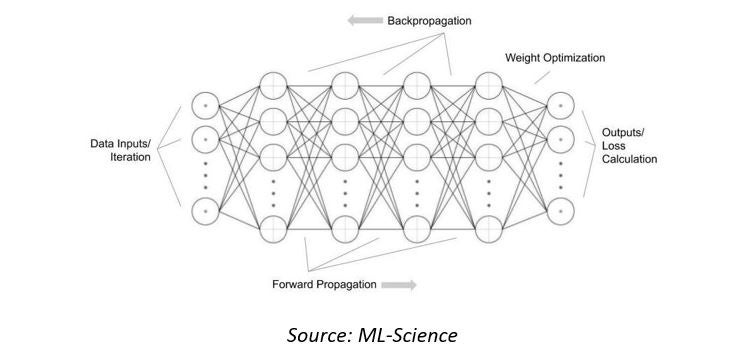
The approach to achieving weak AI has typically revolved around the use of artificial neural networks, which are systems inspired by the biological neural networks that constitute animal brains. They are a collection of interconnected nodes or neurons, combined with an activation function that determines the output based on the data presented in the ‘input layer’ and the weights in the interconnections. To adjust the weights in the interconnections so that the ‘output’ is useful or correct, the network can be ‘trained’ by exposure to many data examples and ‘backpropagating’ the output loss.
Arguably, there is a third branch called ‘neuro-symbolic AI’, in which neural networks and rule-based artificial intelligence are combined. While promising and conceptually sensible, as it seems closer to how our biological brains operate, it is still in its very early stages.
Is it really all about scale?
The crux of the current debate is whether or not with enough scale AI and machine learning models can actually achieve artificial general intelligence (AGI), completely doing away with symbolic AI. Is it now just a hardware scaling and optimization problem, or is there more we need to discover and develop in AI algorithms and models?
Tesla seems to also be embracing the Google/DeepMind perspective. At its Artificial Intelligence (AI) Day event in 2021, Tesla announced the Tesla Bot, also known as Optimus, a general-purpose robotic humanoid that will be controlled by the same AI system Tesla is developing for the advanced driver-assistance system used in its cars. Interestingly, CEO Elon Musk said that he hopes to have the robot production-ready by 2023 and has claimed that Optimus will eventually be able to do “anything that humans don’t want to do”, implying he expects AGI to be possible by then.
However, other AI research teams — prominently including Yann LeCun, Chief AI Scientist at Meta and NYU Professor, who prefer the less ambitious term Human-Level AI (HLAI)—believe that there are still a lot of problems to be resolved and that sheer computational power will not address them, possibly requiring new models or even software paradigms.
Among these problems there are the machine’s ability to learn how the world works by observing like babies, to predict how to influence the world through its actions, to deal with the world’s inherent unpredictability, to predict the effects of sequences of actions so as to be able to reason and plan, and to represent and predict in abstract spaces. Ultimately, the debate is whether this is achievable via gradient-based learning with our current artificial neural networks alone, or if many more breakthroughs are required.

While deep learning models indeed manage to make ‘key features’ emerge from the data without human intervention, and thus it is tempting to believe that they will be able to unearth and solve the remaining problems with just more data and computational power, it might be too good to be true. To use a simple analogy, designing and building increasingly faster and more powerful cars would not make them fly, as we need to fully understand aerodynamics to solve the flying problem first.
Progress using deep learning AI models has been impressive, but it is worth wondering if the bullish views of the weak AI practitioners are not just a case of the Maslow’s Hammer or ‘law of instrument’, which states that “if the only tool you have is a hammer, you tend to see every problem as a nail”.
Game over or teaming up?
Fundamental research like that carried out by Google/DeepMind, Meta, or Tesla usually sits uncomfortably at private corporations, because although their budgets are large, these organizations tend to favor competition and the speed to market, rather than academic collaboration and long-term thinking.
Rather than a competition between strong and weak AI proponents, it might be that solving AGI requires both approaches. It is not farfetched to make an analogy with the human brain, which is capable of both conscious and unconscious learning. Our cerebellum, which accounts for approximately 10% of the brain’s volume yet contains over 50% of the total number of neurons, deals with the coordination and movement related to motor skills, especially involving the hands and feet, as well as maintaining posture, balance, and equilibrium. This is done very quickly and unconsciously, and we cannot really explain how we do it. However, our conscious brain, although much slower, is capable of dealing with abstract concepts, planning, and prediction. Furthermore, it is possible to acquire knowledge consciously and, via training and repetition, achieve automation—something that professional sportsmen and sportswomen excel at.
One has to wonder why, if nature has evolved the human brain in this hybrid fashion over hundreds of thousands of years, a general artificial intelligence system would rely on a single model or algorithm.
Implications for society and investors
Irrespective of the specific underlying AI technology that ends up achieving AGI, this event would have massive implications for our society—in the same way that the wheel, the steam engine, electricity, or the computer had. Arguably, if enterprises could completely replace their human workforces with robots, our capitalist economic model would need to change, or social unrest would eventually ensue.
With all that said, it is likely that the ongoing debate is a bit of corporate PR and in fact AGI is further away than we currently think, and therefore we have time to resolve its potential implications. However, in a shorter timeframe, it is clear that the pursuit of AGI will continue to drive investment in specific technology areas, such as software and semiconductors.
The success of specific use cases under the weak AI framework has led to increasing pressure on the capabilities of our existing hardware. For instance, the popular Generative Pre-Trained Transformer 3 (GPT-3) model OpenAI launched in 2020, which is already capable of writing original prose with fluency equivalent to that of a human, has 175 billion parameters and takes months to train. Arguably, several of the existing semiconductor products today—including CPUs, GPUs, and FPGAs—are capable of computing deep learning algorithms more or less efficiently. However, as the size of the models increase, their performance becomes unsatisfactory and the need for custom designs optimized for AI workloads emerges. This route has been taken by leading cloud service vendors such as Amazon, Alibaba, Baidu, and Google, as well as Tesla and various semiconductor start-ups such as Cambricon, Cerebras, Esperanto, Graphcore, Groq, Mythic, and Sambanova.





