

Big Data refers to large, diverse data sets that, when analysed computationally, can reveal patterns, trends and associations, especially relating to human behaviour and interactions. So what is Big Data in business and why is it important?
Too much data is scattered across too many formats. This data is only valuable to businesses and consumers if it can be analysed accurately and efficiently. For instance, streamed data – which is data in motion – can create business opportunities if it could be analysed quickly enough. An online retailer, for example, can use Big Data to make a recommendation to a customer while the customer is browsing the online store.
Go deeper with GlobalData


Access deeper industry intelligence
Experience unmatched clarity with a single platform that combines unique data, AI, and human expertise.
Big Data is a combination of structured data and unstructured data at scale and at speed. Structured data can be compartmentalised into fields, such as age, height or gender, in a relational database. Unstructured data refers to data that cannot be analysed in a relational database, such as video or tweets. The trick is ensuring the accuracy, reliability and legibility of this data.
Big Data therefore typically has four dimensions: volume because there is a lot of it, velocity, as it needs to be analysed quickly, variety because it comes in many different formats, and veracity because it can be difficult to understand.
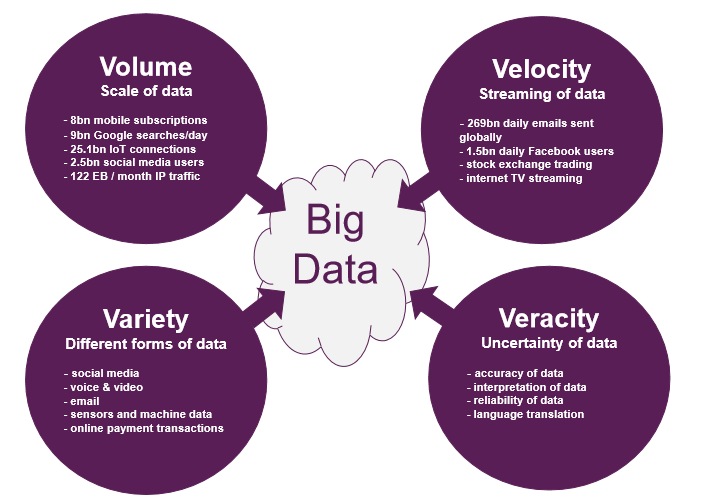
Why does Big Data matter to business?
The challenge for enterprises is not collecting data, but deriving actionable insight from the wealth of information that they accumulate on a daily basis. This is where Big Data technologies come in.
Big Data has applications across industries, from providing detailed customer profiles for retailers to improving the drug discovery process through the use of predictive modelling.
The Big Data value chain

Big Data generation
Big Data is produced by the digital activity of all sorts: call records, emails, sensor activity, payments, social media posts, photos, videos, and much more. It is also produced by machines, both hardware and software, in the form of machine-to-machine (M2M) exchanges of data, particularly important in the Internet of Things (IoT) era, where devices talk to each other without any form of human prompting.
Many of the technology cycles that are taking off now are inextricably linked with this explosion in Big Data. These cycles include AI, virtual reality, internet TV, MedTech and IoT, which covers a range of areas including the connected car, the automated home, wearable technology and ambient commerce.
Big Data management
Big Data is typically managed in data centres, either in the public cloud, in corporate data centres or in end devices. Broadly speaking, the objective of Big Data management is to secure the data, through the use of data governance and security technology, gather insights from the data, using data analysis and business intelligence tools, and manage the data by applying storage, processing, aggregation, and integration techniques.
Given that Big Data can only be of value to consumers and enterprises if it is reliable, robust and secure, the management segment of the value chain is of vital importance to the theme as a whole.
Big Data product development
Once the data is stored, processed, secured and analysed, it can be put to use within a raft of Big Data-infused products. Ad tech companies like Google and Facebook use it to sell digital marketing tools that target users based on their digital profiles. Manufacturing companies like GE use it to monitor the performance of their machines. Business intelligence tools by the likes of Oracle use data to make operational decisions and AI engines such as IBM Watson use it to answer queries at extremely high speeds.
Big Data consumption
These Big Data products are then consumed by several categories of users. For instance, chief marketing officers use them to target advertising campaigns more effectively. Chief operating officers use them to run their business processes more efficiently. Chief engineers use them to improve machine performance and chief scientists use them for predictive analysis in research projects. Machine learning engines like Amazon’s Alexa use them for training purposes, to improve the quality and accuracy of their responses.
What are the big trends around Big Data?
Central governance
Many Big Data vendors have had to contend with a growing market perception that data governance, security, and management have taken a back seat to accessibility and speed. In response, many companies are now accepting the challenge and openly prioritizing data governance. This may result in more active partnerships with outside providers or even acquisitions. It will also require vendors to fully embrace the fact that central data management and governance is instrumental in helping companies build a single version of the truth.
Data privacy and data protection
The misuse and mishandling of personal data is currently a hot topic, thanks in large part to the scandal involving Facebook and Cambridge Analytica. Increased regulation around the storage and processing of data is highly likely – indeed, it is already underway in Europe in the form of the General Data Protection Regulation (GDPR), which came into force in May 2018. Many technology areas are reliant on large data sets and any restrictions on their ability to use them could have significant consequences for future growth.
Downstream analytics
Within vertical markets such as retail, where a sale can be won or lost in a matter of moments, there is no other way to make the necessary rapid-fire decisions, such as which offer to display for a specific customer as he or she enters a store. These decisions cannot wait for such transient events to be uploaded to the company’s cloud, so cloud providers such as Microsoft are revamping their own platforms to push critical analytics functions, such as predictive artificial intelligence (AI) algorithms, downstream to devices.
AI for data quality
One of the benefits of blending AI and predictive analytics is that it can greatly improve data quality. This improvement is greatly needed within any analytics-driven organization where the proliferation of personal, public, cloud, and premises data has made it nearly impossible for IT to keep up with user demand. Companies want to improve data quality by taking an advanced design and visualization concepts typically reserved for the final product of a business intelligence (BI) solution, namely dashboards and reports, and putting them to work at the very beginning of the analytics lifecycle. Instead of simply making sure a data set is clean and appropriate to the task at hand, users can also apply data visualisation tools themselves to the task of data preparation.
AI-ready data
In an effort to speed time-to-market for custom-built AI tools, technology vendors are introducing pre-enriched, machine-readable data specific to given industries. Intended to help data scientists and AI engineers, these data “kits” are not simply a set of APIs or development frameworks aimed at building a user experience. Rather, they include the data necessary to create AI models in a form that will speed up the creation of those models. For example, the IBM Watson Data Kit for food menus includes 700,000 menus from across 21,000 US cities and dives into menu dynamics like price, cuisine, ingredients, etc. This information could be used directly in, say, an AI travel app that enables the user to locate nearby establishments catering to their specific dietary requirements, such as gluten-free bakeries.
Data heterogeneity
Enterprise data no longer resides within a single, large-scale data lake. Analytics tools are increasingly being called upon to access and analyse a wide spectrum of data sources, like Big Data repositories, data services, even spreadsheets, and data types and speeds, structured and unstructured, at rest and in motion.
3 Hardware technology trends impacting Big Data
Cloud adoption
For data and analytics offerings, the cloud is no longer a future opportunity but a current requirement as enterprises seek to share select workloads and data repositories across premises and online.
Edge computing
Specific use cases of edge computing – in which more data processing is done at the edge of the network, nearer to the data source, thereby reducing latency and enabling actions to be triggered in real-time – including the maintenance of data processing and analytics close to points of collection. The growth and evolution of edge computing is therefore closely associated with the IoT. The proliferation of enterprise IoT initiatives will drive demand for edge computing solutions and strategies, with the distributed network of connected IoT objects and devices requiring an equally distributed network of edge devices with data processing, analytics, and, in some cases, storage capabilities. The deployment of 5G cellular technologies will be a major stimulus for both IoT and edge computing.
Quantum computing
The race to reach quantum supremacy, the point at which a quantum computer can carry out calculations faster than a classical computer ever could, is well underway, with Google, IBM and Microsoft leading the pack. AI, and particularly machine learning, stands to benefit, as quantum computers should be able to complete extremely complex calculations, involving very large data sets, in a fraction of the time it would take today’s machines. For effort-intensive AI chores like classification, regression and clustering, quantum computing will open up an entirely new realm of performance and scale
What is the history of Big Data?
Before 1980, companies used mainframe computers to store and analyse data.
Two key technologies were critical to the first formations of data centres as we think of them today. Both occurred in the early 1980s, the first was the advent of personal computers (PCs), which proliferated as Microsoft’s Windows operating software became the global standard. The second was the development of the network system protocol by Sun Microsystems which enabled PC users to access network files. Thereafter, microcomputers begin to fill out mainframe rooms as servers, and the rooms become known as data centres.
A number of critical milestones since then changed the course of the data centre industry’s evolution.
By 2000, VMware had started selling virtualization software, which split servers, which are just industrial scale PCs, into several virtual machines. Virtualisation software made data centres cheaper to run and capable of handling far more applications.
In 2002, Amazon created Amazon Web Services (AWS) as an internal division within its IT department tasked with making its use of data centres more efficient. By 2006 AWS, having transformed the efficiency of its own IT operations, started offering infrastructure-as-a-service (IaaS) to corporate customers. This put cloud computing within the reach of every business, whether it was a multi-national or a one-man-band.
In 2007, Apple kick-started the mobile internet as we know it today with the launch of the first mass-market smartphone with multiple apps, a touchscreen and a revolutionary mobile operating system known as iOS. Google soon responded with its own version, Android. With many of the iOS and Android apps running their internet services from the cloud, a number of internet-facing data centres sprang up.
According to Cisco, by 2017 internet traffic was growing at 24% per annum globally and over 80% of it was generated from consumer data, largely from internet-facing data centres such as those run by Facebook, Alibaba or Google.
This surge in internet protocol (IP) traffic meant that data speeds had to rise to enable data centres all around the world to talk to each other, north-south traffic, and to communicate internally, east-west traffic.
In 2016 and 2017, many data centre operators decided to upgrade their optical interconnect equipment so that data transfer speeds could increase from 40G to 100G, which refers to a group of computer networking technologies for transmitting data in a network at a speed of 100 gigabytes per second.
By the end of 2017, around 30% of data centres worldwide had migrated to 100G.
In 2018, many leading data centres will have started migrating to 400G.
Also in 2018, the use of silicon photonics, a technology that allows chips to talk to each other using optical rays rather than electrical conductors, might transform the speed and economics of data centres.
The Big Data story… … how did this theme get here and where is it going?
- 1946: ENIAC, the first electronic computer, switched on to store artillery codes.
- 1954: First fully transistorised computer to use all transistors and diodes and no vacuum tubes.
- 1960: IBM System Series of mainframes is born.
- 1971: Intel’s 4004 becomes the first general purpose programmable processor.
- 1973: Xerox unveils the first desktop system to include a graphical user interface and large internal memory storage.
- 1977: ARCnet introduces the first LAN at Chase Manhattan connecting 255 computers across a network at data speeds of 2.5Mbs.
- 1981: PC era begins.
- 1981: Sun Microsystems develops the network system protocol to enable the client computer user to access network files.
- 1982: Microcomputers begin to fill out mainframe rooms as servers and the rooms become known as data centres.
- 1999: The dotcom boom, with its demand for fast connectivity and non-stop operations, turns the data centre into a service centre.
- 2000: VMware begins selling VMware workstation, which is similar to a virtual PC.
- 2002: Amazon begins the development of infrastructure-as-a-service (IaaS) at Amazon Web Services (AWS).
- 2006: AWS starts offering web-based computing infrastructure services, now known as cloud computing.
- 2007: Apple launches first iPhone, kicking off the smartphone industry and creating the mobile internet as we know it today.
- 2010: First solutions for 100G Ethernet are introduced.
- 2011: Facebook launches Open Compute Project (OCP) to share specifications and best practice for energy efficient data centres.
- 2012: Surveys suggest 40% of businesses in the US are already using the cloud.
- 2012: Docker introduces open-source OS container software.
- 2015: Google and Microsoft lead massive build-outs of data centres, both for their own use and to sell as IaaS services.
- 2016: Google spends over $10bn in CapEx, mostly on data centres.
- 2016: Alibaba becomes the world’s fastest growing cloud services company, with revenues rising by nearly 200% to $685m.
- 2017: Intel demos 100G silicon photonic transceiver plugged into OCP compliant optical switch.
- 2017: 30% of data centres migrate to 100G data speeds and an ensuing shortage of optical interconnect parts materialises.
- 2017: Huawei and Tencent join Alibaba in major data centre build-outs in China.
- 2017: First 400G optical modules for use in a data centre and enterprise applications become available in the CFP8 form factor.
- 2017: Big inventory pile-up of optical gear in China is largely responsible for volatility among optical interconnect stocks.
- 2018: Leading data centre operators start the migration to 400G data speeds.
- 2018: Massive China infrastructure upgrade begins, led by China Mobile and China Unicom.
- 2018: Silicon photonics technology starts to impact data centre networking architectures positively.
- 2020: Edge computing (micro-data-centres embedded in devices) revises the role of the cloud in key sectors of the economy.
- 2020: Interconnect sector reshaped by a combination of silicon photonics, DIY data centre designs with contract manufacturers and M&A.
- 2021: Over 450 hyper-scale data centres operate worldwide, according to Synergy Research.
- 2021: Data centre speeds exceed 1,000G.
- 2025: Data centres will be increasingly in-device.
This article was produced in association with GlobalData Thematic research. More details here about how to access in-depth reports and detailed thematic scorecard rankings.




